[STRUCE1] 3. laboratorijska vježba - 2021/2022
Zero
Jel se ovaj labos prezentira sljedeci tjedan ili poslije ispita?
Ollie
Kako bi trebali azurirati \ Δw_0 prema ovom algorimu u liniji 6?
Nema mi smisla da na isti način azuriram \ Δw_0 i Δ\mathbf{w}

lucylu
Ollie algoritam iz videa ima raspisano za svaku deltu posebno

Ollie
lucylu e tenks, ali jel ovaj Δ\mathbf{w_0} neki vektor (jer je napisan tak boldano) ili je to sam obični \ Δw_0?
ja sam uzela da je to samo običan \ Δw_0 i ispadaju mi ok rezultati
[obrisani korisnik]
Me hmm ja dobivam kao kolega kad mi je max_iter == 2000, i ne breaka mi zbog uvjeta, a kad povećam broj iteracija na npr. 4000 -> breaka zbog uvjete i dobijem težine:
[ 7.73426648 -2.38474752 0.46232798]
Me1
[obrisani korisnik] racunao sam cross_entropy_error, i njega onda gledao dal se promijenio, onda ja ubiti dodatno dijelim sa 1/N, a pretpostavljam da ste ti i kolega racunala zbroj loss-ova. Mislim da je vase tocno, moze neko potvrdit samo.
lucylu
Ollie mislim da može biti i običan taj w0
[obrisani korisnik]
također, dobijem pogrešku od 0.38, a plottano mi izgleda ok:
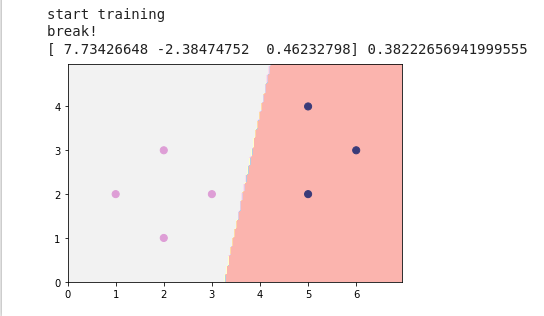
imao netko nešto slično?
micho
Me Eh zanemari što sam napisao ranije.
Okej je i jedno i drugo za taj zadatak. Što je točnije ovisi o definiciji točnosti i problemu, oba načina mogu imati i boljke i nedostatke. U praksi ljudi više vole uprosječivanje i ono se koristi za taj grupni gradijentni spust da gradijent ne ovisi o broju primjeraka.
Skenk
Kak vam izgleda dio koda za plotat granicu u 1.c)? Algoritam mi daje dobre tezine / cross_entropy_error al me konstantno zeza “reshape” kod plotanja.
Skenk
Skenk nema veze, uspio
SuperSjajan3
Skenk moze podijelit kako si uspio ovo, dosta vremena sam vec izgubio na ovome
[obrisani korisnik]
jel za cross_entropy_error u dijelu s regularizacijom dodajemo reg. faktor? odnosno jel nam se regularizacija svodi samo na weight decay pribrojnik?
bjunolulz
Skenk kako si popravio
Daho_Cro
Jeste li u drugom zadatku koristili ugrađenu logističku regresiju(LogisticRegression) ili onu koju smo mi morali napisati tj. lr_train?
bodNaUvidima
Možete napraviti razred CustomModel kojem predajete dobivene težine u konstruktoru. U tom razredu ponudimo funkciju predict(X) koja vraca np.array u kojem se nalaze predikcije za svaki primjer u X, uz zapamćene težine w.
Na kraju, poziv plot funckije može izgledati nekako ovako:
plot_2d_clf_problem(X, y, lambda x: customModel.predict(x) <= 0.5)
Ako vam se pojave greške radi različitih dimenzija w i x vodite računa o preslikavanju x unutar lambda funckije u Φ(x).
Skenk

angello2
u 1.e) i 2.a) dobim identicnu granicu izmedu klasa. S obzirom da ispod stoji pitanje “Zašto se rezultat razlikuje od onog koji je dobio model klasifikacije linearnom regresijom iz prvog zadatka?” pretpostavljam da ne bi tak trebalo bit? mislim koristio sam LogisticRegression u oba zadatka ne vidim sta sam mogo krivo napravit
angello2
angello2 evo skuzio sam sam, u drugom izleda treba radit sa svojom funkcijom.
kako vam izgleda graf u 3.? jel normalno da jedino za a=0 dobimo oke rjesenje a ostala su sva losija?
mbeno2358
angello2 S obzirom da ispod stoji pitanje “Zašto se rezultat razlikuje od onog koji je dobio model klasifikacije linearnom regresijom iz prvog zadatka?”
Pretpostavljam da se taj dio odnosi na prethodni lab jer smo u njemu klasificirali pomocu lin. reg. Mozda su ta dva labosa bila zajedno prije pa su zaboravili to updateat.
[obrisani korisnik]
angello2 ovako je meni ispalo:
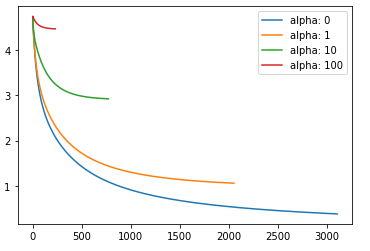
steker
u 1 e) ovaj C parametar u logistic regression bi trebo bit neki dosta velik broj??