[STRUCE1] 4. laboratorijska vježba - 2021/2022
sheriffHorsey
fer999 vjerojatno ti se to događa jer nisi poslao np.array nego običnu listu
viliml
Sulejman
Jel i vama ispadnu svi histogrami ovak:

jedino kaj se mijenja su vrijednosti na osima… Ak da ne kužim šta oni misle pod “Dobiveni histogrami su vrlo slični.”
Ducky
Kako koristit mlutils.plot_error_surface?
Izbacuje mi:
AttributeError: module ‘mlutils’ has no attribute ‘plot_error_surface’
Rjesio: treba maknut mlutils
Ducky
Kolko vam ispadaju C i gamme u 3.?
Sulejman

sheriffHorsey
SuperSjajan3 Sto ti je svijetlija boja na grafu to ti oznacava manju pogresku, sto je tamnija to je pogreska veca. Tipa na ovom Sulejman gornjem lijevom grafu sto je veci c i gama, model je slozeniji pa je i pogreska manja/podrucje svjetlije (gornji desni kut tog grafa). Na test setu tj. gornjem desnom grafu je za isti taj c i gama ocekujes nesto tamniju boju za te iste hiperparametre tj. vecu pogresku na test setu. Podnaucenost onda bude tamo gdje je podrucje crno i za test i za train graf tj. pogreska je velika na oba, a prenaucenost tamo gdje je na train grafu svjetla boja tj. mala pogreska i na test grafu sve tamnija boja tj. veca pogreska. Ja sam tako nekako interpretirao i bilo je u redu.
ovo su jos neka pitanja za svm koja su me pitali:
sto su potporni vektori?
kako outlier utjece na svm?
kako se linearni svm nosi s nelinearnim podacima?
koliko potpornih vektora ima na zadnjem plot u 1.c?
kako hiperparametar c utjece na slozenost modela?
objasni graf u 3.b, jeli povrsina pogreske razlicita i gdje je pod/prenaucenost na tom grafu?
sto radi minmax scaler i kako se nosi s outlierom?
sto radi standard scaler?
[obrisani korisnik]
ima netko ideju zasto bi mi 1. i 3. ispali ovako? ne čini mi se baš ok:

Daeyarn
[obrisani korisnik] tako je i meni
lovro
[obrisani korisnik] jel zna neko objasnit šta se tu događa na prvom i trećem grafu u prvom retku?
[obrisani korisnik]
Daeyarn a jel ikom jasno zašto je tako? 😅
bodNaUvidima
[obrisani korisnik] Zbog jačine regularizacije. Za linearan model koji je ionako već preograničen za ove primjere regularizacija ga onesposobi do kraja. Isto se dogodi kod rbf-a kojeg preograniči da uspije pronaći parametre koji bi nešto odvojili.
[obrisani korisnik]
jel itko dobivao ovakve grafove u 3.?
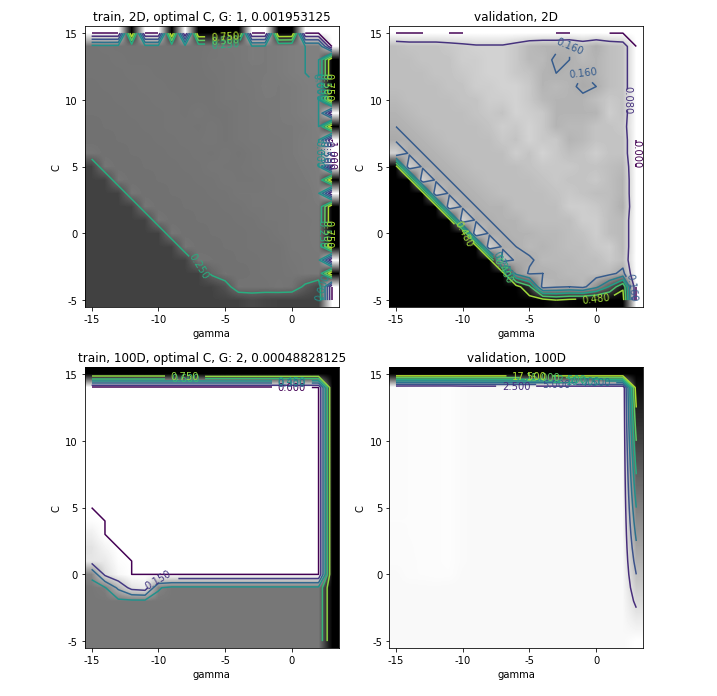
tomekbeli420
Funkcija treba vratiti optimalne hiperparametre (C^*,\gamma^*) , tj. one za koje na skupu za provjeru model ostvaruju najmanju pogrešku.
Na koju pogrešku se ovo misli? Hinge? 0-1?
bodilyfluids
tomekbeli420 Pretpostavljam 0-1 jer matrice pogrešaka koriste taj
[obrisani korisnik]
tomekbeli420 mislim da se moze i sa accuracy_score posto je i on importan u tom dijelu labosa
bodilyfluids
[obrisani korisnik] mislim da to, bar u ovom labosu, dode na isto kao 0-1
Ardura
Je li 4.zad treba ispasti ovako nekako?

angello2
Maddy trebalo bi bit dosta manje za neskalirane skupove
bodNaUvidima
Maddy Trebala bi bit veca razlika kod skupa za ucenje i skupa za provjeru za sva 3 (ne)skalirana slucaja, to je onako prvo sto mozda ne valja.
I trebala bi biti manja greska kod skaliranih modela nego kod neskaliranog.

Meni ispada ovako u prosjeku kad koristim onaj hinge loss iz ranijih zadataka.
Ardura
Maddy Ako netko jos ima problem da mu je neskalirani tocniji od drugih u make_classification treba maknuti random_state!!!
Ardura
[obrisani korisnik]
Maddy greska manja, tocnost veca heh