[PUS] 1. laboratorijska vježba - 2021/2022
Amon
Hadoop instalacija za Windows
by Amon
Uvod:
Ovaj guide pišem kako bih olakšao živote svih koji se struggleaju sa instalacijom ovog labosa. Ja sam osobno izgubio par dana da skužim kako se settupa ovaj cijeli clusterfuck od labosa.
Prvo sam ga probao instalirati na Linux virtualci (jer Hadoop kao podržava Linux), ali je bilo problema s podešavanjem portova (što vjerujem da problem zbog toga što sam koristio virtualku a ne pravi Linux) tako da ne preporučujem takav pristup i držite se Windowsa (kako pri ovom labosu tako i u životu :)
Inače, ovaj guide je napravljen prema uputama s ove stranice:
https://kontext.tech/column/hadoop/377/latest-hadoop-321-installation-on-windows-10-step-by-step-guide
Samo što ovdje imam određene izmjene i poboljšanja (i stvari koje tamo ne pišu, a potrebne su za ovaj labos)
0.1. Prije same instalacije potrebno je poduzeti određene mjere. Prva i osnovna jest provjeriti ima li vaš user folder dijakritike. Dakle ići na C:\users i provjeriti ima li user folder dijakritike. Ako nema prijeđite na sljedeći korak. Ako ima… Well tough luck, ali morat ćete ih se riješiti jer će Hadoop raditi neke foldere u user folderu, a nije sposoban pročitati dijakritike (UTF-8 je ipak malo prenapredan za ovaj program).
Za to imate 2 opcije. Opcija br. 1 je ručni rename user foldera, samo pratite korake sljedećeg videa:
Ali tu ima problem a to je da neki programi imaju hardkodiranu vrijednost user foldera pa ćete ih morati opet namještati kada ih budete pokretali, npr. tako je bilo meni sa Visual studiom (and yeah, ja sam bio jedan od tih s dijakriticima u user folderu).
Druga opcija (koja je u teoriji puno bolja) je stvaranje novog user accounta bez dijakritika jer će se onda za njega stvoriti njegov vlastiti user folder i dalje tamo radite sve kao u ostatku ovog guidea. Zašto ja nisam to napravio? Jer sam se tek sad sjetio da bi to moglo funkcionirati. Naravno, ova opcija je puno bolja, ali je nisam testirao (pa ako ju netko testira neka slobodno javi), dok opcija br. 1 sigurno radi.
0.2. Za pokretanje ovog programa trebate imati javu. Aku ju kojim slučajem nemate (and shame on you if you don’t), onda pogledajte ovaj guide https://www.guru99.com/install-java.html. U cmd upišite java -version i morate dobiti nešto ovakvo:

Ali i ako to piše, još niste oslobođeni ovog dijela s javom. Naime, morate provjeriti imate li u system varijablama zapisanu JAVA_HOME varijablu. Da to vidite odite na search > edit the system environment variables > u otvorenom prozoru imate enviroment variables pri dnu. Tu sad gledajte pod user variables i vidite imate li varijablu JAVA_HOME. Ako ju nemate, dodajte ju tako da napišete path do java filea na vašem kompu. Na kraju dobijete nešto ovakvo:

Ovo je bilo samo zagrijavanje, sad kreče Hadoop dio…
Prvo morate skinuti Hadoop. Gore navedeni guide kaže da skinite verziju 3.2.1., ali problem je što ta verzija ima neki bug koji ima gomilu posla da se razriješi, a verzija 3.2.2. ga više nema tako da skinite tu verziju. Link za tu verziju nalazi se ovdje:
https://www.apache.org/dyn/closer.cgi/hadoop/common/hadoop-3.2.2/hadoop-3.2.2.tar.gz
Nakon toga morate skinuti bin datoteku s ovog linka: https://github.com/cdarlint/winutils/tree/master/hadoop-3.2.2/bin i onda službeni bin datoteku zamijenite s tom.Sada morate napraviti HADOOP_HOME environment varijablu. Dakle treba pratiti sve kao što je bilo i sa JAVA_HOME varijablom i trebate ju dodati da pokazuje u vaš Hadoop folder, kod mene je to ovako:

- At this point, trebali biste moći pogledati prepoznaje li komp Hadoop u cmd-u s naredbom:
hadoop -version i trebate dobiti ovako nešto:

VAŽNO: Svaki put kada napišem da se koristi cmd, morate ga pokrenuti kao administrator. Neke naredbe se neće htjeti pokrenuti inače.
Pronaći core-site.xml file u \etc\hadoop folderu (kod mene je to C:\Programiranje\Hadoop\etc\hadoop) i tamo na dno umjesto onog
<configuration> <\configuration> stavite <configuration> <property> <name>fs.default.name</name> <value>hdfs://0.0.0.0:19000</value> </property> </configuration>Pronaći marped-site.xml file u istom folderu i opet umjesto configuration elemenata trebate staviti ovo:
<configuration> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> <property> <name>mapreduce.application.classpath</name> <value>%HADOOP_HOME%/share/hadoop/mapreduce/*,%HADOOP_HOME%/share/hadoop/mapreduce/lib/*,%HADOOP_HOME%/share/hadoop/common/*,%HADOOP_HOME%/share/hadoop/common/lib/*,%HADOOP_HOME%/share/hadoop/yarn/*,%HADOOP_HOME%/share/hadoop/yarn/lib/*,%HADOOP_HOME%/share/hadoop/hdfs/*,%HADOOP_HOME%/share/hadoop/hdfs/lib/*</value> </property> </configuration>Sada nađite yarn-site.xml u istom folderu i opet zamijenite configuration dio s ovim dijelom:
<configuration> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> <property> <name>yarn.nodemanager.env-whitelist</name> <value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAPRED_HOME</value> </property> </configuration>Napravite folder data u root nodeu (dakle kod mene je to C:\Programiranje\Hadoop). U taj folder stavite novi folder dfs. I na kraju u taj dfs stavite 2 foldera: name i data. Ta 2 foldera će se kasnije koristiti.
Sada odite do \etc\hadoop foldera i nađite hdfs-site.xml file i tamo umjesto configuration dijela upišite:
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:///C:/Programiranje/Hadoop/data/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:///C:/Programiranje/Hadoop/data/dfs/data</value>
</property>
</configuration>Dakle ove pathove fileova koje ste dodali sada morate staviti gore, tamo gdje imamo ove <value> propertyje.
- Sada idite u cmd (admin mode) i pozicionirajte se u bin folder. Tamo upišite naredbu: hdfs namenode -format
Nakon toga biste trebali dobiti dugi zapis u cmd-u koji završava ovako:

Konfiguracija je gotova (basically), ostalo je još samo pokrenuti sve.
Pozicionirajte se u sbin folder i upišite naredbu start-dfs.cmd i trebala bi iskočiti 2 cmd-a. Pričekajte malo i idite na sljedeće linkove i pogledajte ima li na njima nešto:
http://localhost:9870/dfshealth.html#tab-overview
http://localhost:9864/datanode.html
Trebalo bi biti neki preglednik na njima. Nećete ga koristiti ni ništa, ali ako je tamo onda sve valja (za sada).Sada idite u sbin i upišite start-yarn.cmd i trebala bi iskočiti još 2 prozora gdje će se nešto vrtjeti. Ako se ne pokrenu to je možda do toga što imate yarn instaliran na kompu. Ako je tako onda će se yarn na kompu poklat sa yarnom iz hadoopa i to morate riješiti tako da upišete sljedeće naredbe:
@rem start resourceManager
start "Apache Hadoop Distribution" C:\Programiranje\Hadoop\bin\yarn resourcemanager
@rem start nodeManager
start "Apache Hadoop Distribution" C:\Programiranje\Hadoop\bin\yarn nodemanager
@rem start proxyserver
@rem start "Apache Hadoop Distribution" yarn proxyserverna kraj start-yarn.cmd datoteke (otvorite ju s nodepadom).
Pogledajte imate li na sljedećem linku nešto pokrenuto:
http://localhost:8088/cluster
Ako imate nešto onda ste GOTOVI.
Barem s instalacijom…
Završna riječ (čitaj rant) autora:
Očito je da ekipa sa predmeta već par godina ima instaliran Hadoop na kompovima i da ne žele nikako dati neke upute za setup (jer je očito da će izgubiti vrijeme na pisanje takvih uputa, a svi znamo da je value(vrijeme_2_ljudi_na_zavodu) >> value(vrijeme_70 studenata_na_predmetu)) nego su samo otišli na službene stranice od Hadoopa i samo su nam dali link nek se snalazimo (a instalacija je daleko od trivijalne i ako bilo gdje slightly pogriješite basically morate sve ispočetka raditi)
renren
Amon Čovječe, kudos za pomoć oko ovog djela sotone. Kad sam prvi put probala instalirat prije par dana išla sam po drugim random guide-ovima i nije uspjelo. Sad evo iz prve proradilo.
Amon
Moram ovdje napisati par nadoupuna što se tiče ovog svega, par addenduma as one would say jer sam neke stvari krivo napisao/propustio napisati:
1. marped-site.xml file je u forumu bio loše napisan, tj. trebalo je imati * na kraju svake naredbe, a forum je progutao te znakove i onda ne piše kako spada (mićo je kriv za ovo, ne ja)
Dakle pravi marped-site.xml file treba izgledati ovako:
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.application.classpath</name>
<value>%HADOOP_HOME%/share/hadoop/mapreduce/\*,%HADOOP_HOME%/share/hadoop/mapreduce/lib/\*,%HADOOP_HOME%/share/hadoop/common/\*,%HADOOP_HOME%/share/hadoop/common/lib/\*,%HADOOP_HOME%/share/hadoop/yarn/*,%HADOOP_HOME%/share/hadoop/yarn/lib/\*,%HADOOP_HOME%/share/hadoop/hdfs/\*,%HADOOP_HOME%/share/hadoop/hdfs/lib/\*</value>
</property>
</configuration>2. Labose ipak ne možete raditi “samo tako” pišući kod bez importanja klasa nego ćete ipak morati importati .jar fileove u IDE. Fajlovi koje morate dodati nalaze se u poddirektorijima: common, mapreduce i hdfs. Importajte sve dok se ne riješiti import pogrešaka and then you are set to export into .jar kako treba
3. u 2. koraku piše da obrišete data folder ako ne valja. Time sam mislio da obrišete sadržaj data\dfs\data foldera, a greška na koju se referiram je ako piše incompatible cluster ids
4. između koraka 4. i 5. teba dodati još jedan korak, a to je dodati root folder u kojem ćete sve raditi jer one mkdir input i slične komande ne rade bez toga
Dakle trebate dodati još 2 naredbe at that point:
hadoop fs -mkdir user
hadoop fs -mkdir imeUseraNaVašemUserFolderuŽao mi je za moje propuste pri ovom svemu i nadam se da ovim postom mogu ispraviti ove greške
Murin
Svaka cast frende, i ja sam mislio napisati neki guide ali nakon par dana jebanja s ovim nisam vise to mogao gledati.
Samo cu nadodati neke probleme i linkove koji su mi pomogli ako netko zapne
Zaostali simlinkovi zbog kojih ne radi java -version
Pathovi u sys variablama ne rade jer sadrže razmake
Falili su neki propertiyi u hdf.site-xml
treba napraviti hadoop fs -mkdir (direktorij za spremanje)
Ako se builda jar sa Intellj-om zip -d <ime>.jar META-INF/LICENSE
-Ako koristite intellj nemojte raditi nikakav poseban package, negos ve src/main/java (ili kako vec ide)
-cmd se pokrece kao administrator
-kod onih winutilsa najbolje sve prekopirat u bin
Koristio sam savjete od kolega iz proslih grupa + ovaj site
Amon
Kako raditi labos
Labos se može raditi u eclipseu (ili nekoj drugoj java razvojnoj okolini) gdje će vam javljati import errore jer ne prepoznaje importe koje imamo u primjeru. Te greške morate riješiti prije eksportanja fajlova, a to radite tako da importate jar fileove s tim klasama. Sve importove imate u share\common, share\mapreduce i share\hdfs datotekama (jako puno je jar fileova u poddirektorijima i sve ih morate importati kroz razvojnu okolinu, u mom slučaju eclipse)
Za kraj imam redom naredbe koje morate koristiti za pokretanje labosa. Za izradu labosa pozicionirajte cmd u bin folder i od tamo ćete sve raditi.
- hdfs namenode -format
- obrisati data folder ako javi grešku pri pokretanju
- sbin/start-dfs.cmd
- sbin/start-yarn.cmd
- napraviti projekt u eclipseu
- export u jar i staviti u neku mapu (može i u bin mapu)
- izbrisati input i output datoteku hadoop fs -rm -r output i tako za input (ako postoje)
- napraviti input datoteku hadoop fs -mkdir input
- staviti txt datoteku (npr log.txt) u bin mapu (to je naš input)
- staviti datoteku u input hadoop fs -put log.txt input/log.txt
- pokrenuti sve s naredbom: hadoop jar putanjaDoJarDatoteke.jar imeKlase input/ output/
- hadoop fs -ls output za vidjeti izlaz
- hadoop fs -cat output/part-00000 da vidimo rezultat
- u 3. zadatku trebate napraviti temp dir (dakle hadoop fs -mkdir temp) kojeg ćete koristiti za kao međukorak za izradu 3. (ali i 4. zadatka) kojega treba obrisati kao i input i output dir prije ponovnog pokretanja svega
- Primjer korištenja temp dir-a da output jednog joba ida na input drugog:

part-00000 datoteka se sama stvara, temp file mora biti prazan kada se uključi program. To je jedan od razloga zašto ga morate obrisati i ponovno napraviti pri svakom pokretanju.
-Ivan-
Amon Je li možeš molim te print screenat sve jarove koje si importao jer ja nemrem nikako kompajlirat ovo u eclipsu da bi mogao exportat (sve do tog normalno dela)
duckyy
Labos nije potrebno nigjde predati prije termina vec samo tamo pokazemo kako radi?
carantena
Amon jel možeš molim te objasnit ovo zadnje, između koraka 4. i 5. , gdje napravit taj root folder i što u njemu sve trebamo imat? ove naredbe zovemo kad se pozicioniramo u tom novom folderu?
Hvala!
MJ3

Zbog nekih errora sam downgradeala na javu 1.8, promijenila JAVA_HOME u user variables (u path promijenila i lokaciju bin foldera jave). Nakon ovoga java -version ispisuje verziju 1.8, dok javac -version i dalje izbaci 12.0.2
Jel zna netko u čemu može biti problem?
Amon
MJ3 My guess je da ti je ostala varijabla od prijašnje instalacije na Path varijabli (ona ti se nalazi među system variables, dakle ispod onih user varijabli). Nađi si tamo putanju koja ti je vodila na ovu prošlu verziju jave i promijeni ju na istu putanju koju imaš za JAVA_HOME
harry_pointer
Ima neko možda iskustva s java.lang.UnsatisfiedLinkError kod start-dfs naredbe? Sve radim po uputama i jednostavno ne znam u čemu je problem😥
pepelko
harry_pointer Ja imam isti problem, DataNode se ruši s tom porukom i nemam pojma u čemu je problem 🙁 jel ti možda proradilo?
Ducius
jel ima netko da kod pokretanja jar file dobije ovakav error?
pepelko
EDIT:
Upravo proradilo.. problem je bio u krivo definiranom pathu do data foldera u hdfs-site.xml file-u. Tocan path (u mom slucaju) je:
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/User/hadoop/data/dfs/data</value>
</property>harry_pointer
pepelko Mislim da nije u tome problem kod mene, path je okej. Možda je do permissiona, ali mi se čini da i to imam dobro postavljeno. Trenutni workaround mi je da radim na sestrinom laptopu - malo glupo, ali radi haha
421blazeitfgt
Pazite kad radite install da imate bas tocno javu 8 ja sam imao neku drugu i nis nije radilo
https://stackoverflow.com/questions/44427653/hadoop-error-starting-resourcemanager-and-nodemanager
pepelko

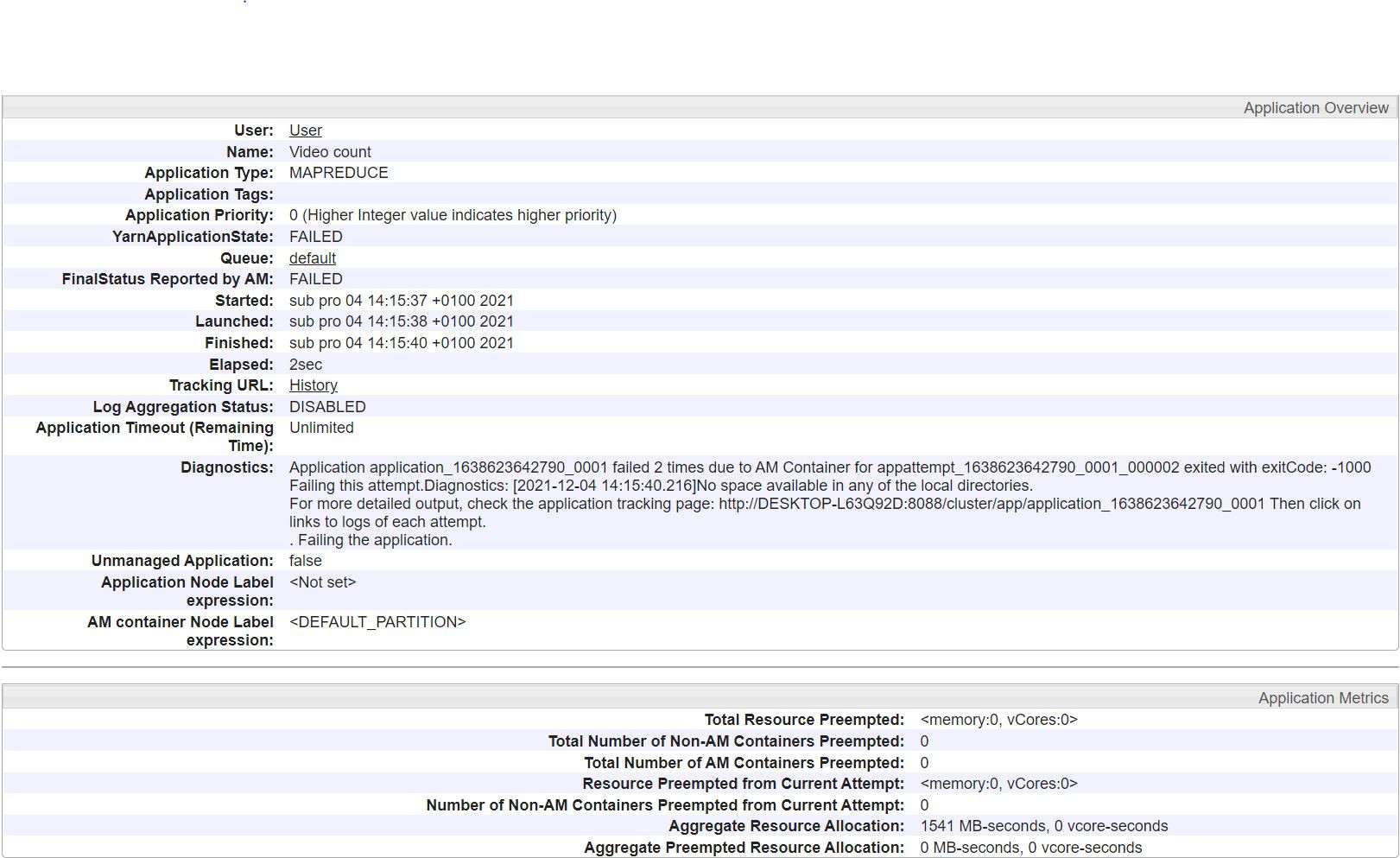
Jel netko zna mozda kako rijesit ovo?
"Application application_1638623642790_0001 failed 2 times due to AM Container for appattempt_1638623642790_0001_000002 exited with exitCode: -1000
Failing this attempt.Diagnostics: [2021-12-04 14:15:40.216]No space available in any of the local directories…"
Amon
carantena Samo moraš napraviti taj user folder i subfolder unutra koji ima ime usernamea tvog kompa
PS sad sam skužio da naredbe pišu ko 2 foldera, a trebali bi biti folder i subfolder, dakle odi u cmd, pozicioniraj se u bin folder i samo upišeš sljedeće naredbe i gotovo je s tim korakom, više se ne moraš obazirati na njega:
hadoop fs -mkdir user
hadoop fs -mkdir user/imeUseraNaVašemUserFolderurenren
Evo mojih naredbi koje su uspjele na kraju za pokretanje primjera iz lab-a. Znači nakon što pokreneš sve one naredbe od 1. do 4. koraka uradiš sljedeće:
(unutar bin foldera)
hadoop fs -mkdir /user
hadoop fs -mkdir /user/User
hadoop fs -mkdir input
hdfs dfs -put log.txt input/log.txt
hadoop jar lab.jar VideoCount input/ output/
hadoop fs -ls output
hadoop fs -cat output/part-00000*ovo sve s tim da su je u bin folderu log i jar datoteke
**ime usera može bit šta god, ja sam stavila User onako
***nisam još krenula pokretat sljedeće zadatke, ali kad se rade oni onda se krene od 5. kroaka iz Amonove objave (znači izbrišeš valjda postojeći input i output i staviš log od trenutnog zadatka pa napraviš nove itd)
svemia
Amon Jel treba prije tih naredbi pokrenut start-dfs i start-yarn? Dobivam samo “mkdir: Your endpoint configuration is wrong; For more details see: http://wiki.apache.org/hadoop/UnsetHostnameOrPort”. Cmd mi je u admin nacinu rada.
Svarog
je li tko pokušao dići hadoop preko dockera? naletio sam na ove convenience builds https://hub.docker.com/r/apache/hadoop, pa da ne izgubim previše vremena ako nisu primjenjive za labos
frle10
Ja sam probao, i upravo sam uspio. Koristim Dockefile i docker-compose od ovog autora:
https://github.com/cupgit/docker-hadoop
Malo sam promijenio Dockerfile da mi umjesto verzije 3.0.3 skine zadnju, 3.3.1 i radi savrseno. Lijepo se digne Docker container i mogu pristupit nodeovima preko web sucelja…
Nisam jos pokusao napravit labos do kraja s ovim, ali mucio sam se cijeli dan bzvz ako ovo funkcionira. Ova metoda je bolesno lagana i radi na apsolutno svim sustavima koji god da imate (Windows, Linux, Mac OS X).
Taj image je napravljen da radi u pseudo-distributed modu isto kako u labosu pise da treba apparently tako da eto, preporucam svakome tko vec nije da to proba jer je masno lakse i gotovo u 20 minuta (ako vec imate instaliran Docker i docker-compose).