[STRUCE1] Gradivo
InCogNiTo124
Amajli 1.55 je najblizi 23 tak da je zato xD
Hus
InCogNiTo124 To je to! Hvala! (meni je isto ispadao u trećem 23 pa sam mislio da sam nesto tesko profulao oko gubitka i modela multinomijalne regresije, no izgleda da nisam jedini pa barem nešto)
cotfuse
Hus
4) Ovo prakticki opisuje neuronsku mrezu sa ulaznom dimenzijom 10, skrivenim slojem dimenzije 3 i izlaznim slojem dimenzije 4. Svaki od slojeva ima svoje biase, pa racunica ispada: (10+1)*3 + (3+1)*4 = 49
Osim toga, ovaj zadatak koji je 3. kod husa, tocan odgovor je 23 i u medjuvremenu su promijenili odgovore tako da je sada i 23 ponudjeno.
saitama
cotfuse zasto je skriveni sloj dimenzije 3,a ne 4 ?
Amali
cotfuse 4) Ovo prakticki opisuje neuronsku mrezu sa ulaznom dimenzijom 10, skrivenim slojem dimenzije 3 i izlaznim slojem dimenzije 4. Svaki od slojeva ima svoje biase, pa racunica ispada:
(10+1)*3 + (3+1)*4 = 49
jel ovo gleda da je fi0 dummy pa se ne broji kao dio sloja unutra, a izlaz je 4-dim tj za svaku klasu jedan?
Amali
Amajli sad sam drugi put pokrenula kviz i druga su rjesenja pod tim zadatkom, netko prijavio il oni skuzili I guess
Amali
member dobijes h(x) tak, ispast ce ti simetricni, i sam ih uvrsit u formulu koji god sa suprotnom oznakom od one za koju je dobiven (tipa za y = 1 dobijes jedan broj i taj iskoristis u loss funkciji u clanu za klasu 0. Koju god kombu uzmes dobit ces isto svakako)
tito
zašto funkcija pogreške ne konvergira kod linearne regresije kada su značajke linearno zavisne?
InCogNiTo124
tito u tom slucaju ti matrica dizanja nema puni rang i pseudoinverz ne postoji
Bananaking
Što je onaj VS(H,D) ?
InCogNiTo124
Bananaking version space, prostor inacica, je skup hipoteza koje na datasetu D imaju empirijsku pogresku 0. Takvih moze biti beskonacno.
Primjer ti je tu na slici, ako su ti hipoteze pravokutnici, onda ti je zelena povrsina VS na example datasetu
Stark
Može objašnjenje ovog?

Stark
Amon Hvala, nisam uopće skužio da je već bilo pitanje 😅
YenOfVen
Sto zadnje ulazi u ispit?
Bananaking
YenOfVen 11 - Neparametarske metode
-Ivan-
Je li mi može netko molim vas objasniti kako se ovo rješava?
- Koristimo regresiju za predviđanje uspjeha studija na temelju prosjeka ocjena u četiri razreda srednje škole te uspjeha iz matematike i fizike na državnoj maturi (ukupno 6 značajki). Za preslikavanje u prostor značajki koristimo polinom drugog stupnja s interakcijskim parovima značajki (samo parovi!). Pretpostavite da nema multikolinearnosti. Koliko minimalno primjera za učenje trebamo imati, a da bi rješenje bilo stabilno i bez regularizacije?
-Ivan-
Ivančica (znam da je odgovor 28, ali ne znam zašto)
InCogNiTo124
Ivančica mislim da je do tog da, kad uzmes n varijabli i preslikas ih polinomom drugog stupnja, dobijes n znacajki jednakih originalnim, n(n-1)/2 parova i n kvadrata, za n=6 to je 6+15+6=27 i jos bias za sve skupa 28 znacajki
Minimalno toliko i primjera ti onda treba da ti matrica ima puni rang i da postoji (pseudo)inverz
-Ivan-
InCogNiTo124 Hvala lijepa 😁
Emma63194
InCogNiTo124 Drugi zadatak:
Nadam se da si rjesavao drugi labos koji se ticao logisticke regresije, gdje si uzeo wTx i omotao to oko sigmoide. E sad, sigmoida je poprilicno nelinearna, ali granica koju si (trebao) dobiti je linearna. Zasto je tome tako? Zato jer su ti podaci unutar sigmoide linearni. Dakle, ako ti je funkcija PHI linearna, dobit ces linearnu granicu. Ako je nelinerna, i granica ce bit (perhaps surprisingly) nelinearna. Also, ako ti je PHI nelinearna, a PHI linearna, ponovo granice nije linearna. Podaci su kljuc!
Pročitala sam ovo nekoliko puta i razmislila o tome, ali zaista mi ne sjeda.
Nije mi jasno, ako imamo sigmoidu ili ako je npr. f neka jako divlja nelinearna funkcija (šta ja znam, sinusi, kosinus, apsolutne vrijednosti, šta se već sve da skombinirati u jednu funkciju), kako unatoč tome funkcija uspije dati neku linearnu granicu samo zbog toga što su podaci linearni?
InCogNiTo124
Emma63194 ovo je u biti dobro pitanje, nadao sam se da cete ili uzet to as is, ili ce nekom neka matematicka intucija pomoc, al zaista nije u redu od mene da to ne objasnim.
Kratak odgovor: nelinearnost je u ortogonalnoj dimenziji pa se “ne broji”. Dugi odgovor slijedi u nekoliko skrinova ispod:
Ovo je sigmoida od linearne kombinacije:

ovdje su mi a i b neke “tezine”, a f je sigmoida, nebitno. Bitno je da bi sad klasifikacijska granica bila f(x)=0.5, odnosno presjekli bi ovu plohu sa ravninom z=0.5. Tebi prepustam da si zamislis sto bi dobila: odgovor je lijepi ravni pravac. Razlog tome je sto je funkcija nelinearna kad se gleda po z dimenziji, dok je linearna kad se gleda u x-y dimenzijama.
Novi primjer:
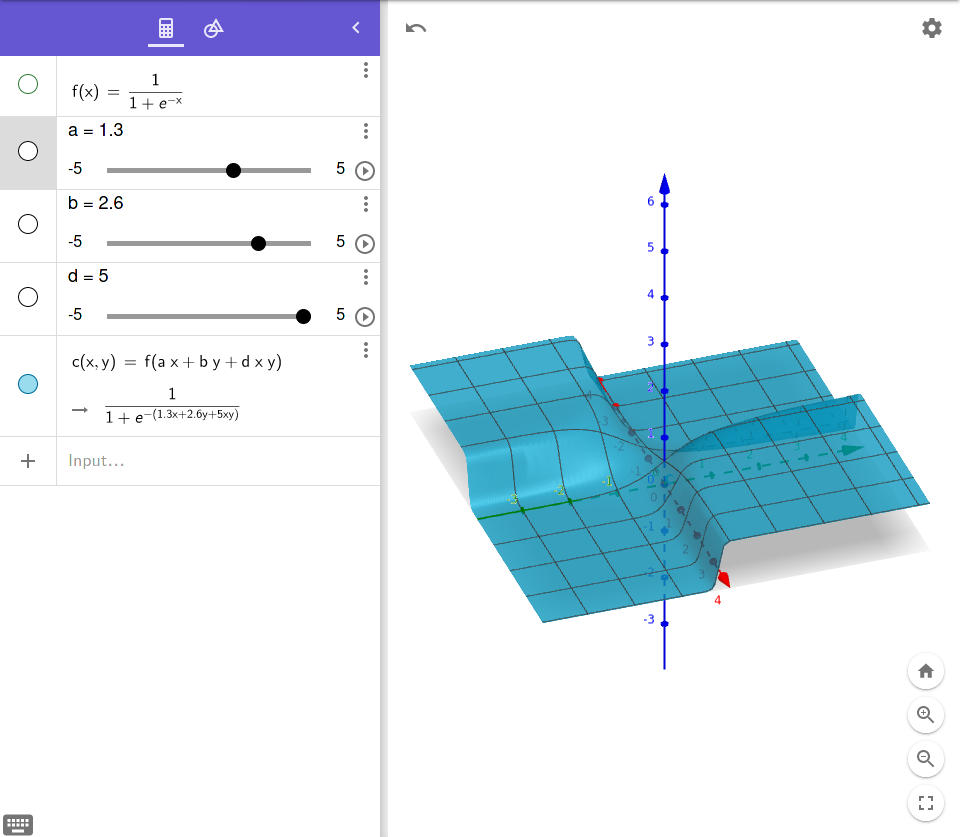
Ovdje ako obratis pozornost na ulaz u sigmoidu, vidit ces da sam promjenio tako da sam dodao “interakcijsku znacajku” - fensi rijec za nelinearnost. Radimo opet istu stvar, presjeces povrsinu sa ravninom z=0.5 i kj dobis ovaj put? ERMAGERD pa crta koju dobis vise nije linearna!! Upravo zbog podataka haha
Zadnji primjer:

Sad sam dodao kvadrate i vidi sta se dobi, slatki mali bulge ^^ naravno kad bi ovo cudo sad presjekla sa z=0.5 dobila bi neku kruznicu. Y iz that? opet nelinearno, samo zato jer su znacajke nelinearne.
TLDR linearna kombinacija znacajki daje linearnu granicu (nakon sto plohu presjecemo ravninom) cak i uz nelinearnu aktivaciju. Ako je kombinacija znacajki nelinearna, granica ce bit nelinearna.