[DUBUCE1] Gradivo
Rene
𝐓𝐇𝐄 𝐒𝐄𝐂𝐑𝐄𝐓 - 𝐂𝐋𝐔𝐁 nismo, to spada u generativne modele i sada se radi na dubuce2
boogie_woogie
Moze netko objasniti ovaj?

ppooww
nika_1999 Formula za parametre LSTM-a je [(skriveni_sloj + ulazni_sloj + 1) * skriveni_sloj] * 4. Jedino sad ne znam jel kakvu ulogu igra cinjenica sto je dvoslojni LSTM.
Rene
nika_1999 Imas 3 propusnice: f, i, o i privremeno stanje \hat{c}. Svaka od njih ima svoje parametre W_{hh}, W_{hx}, b_h .
U prvom sloju W_{hh} je dimenzija HxH dakle 500×500, W_{hx} je dimenzija HxD dakle 500×300 i b_h je dimenzije 500.
U drugom sloju je jedina razlika sto ulazi nisu X nego skrivena stanja prvog sloja, pa je i matrica W_{hx} dimenzije 500×500.
Dakle, ukupno:
4 \cdot (500 \cdot 500 + 500 \cdot 300 + 500 + 500 \cdot 500 + 500 \cdot 500 + 500) = 3604000
Tompa007
sheriffHorsey Sta znaci postavljas prag ?

Rene
𝐓𝐇𝐄 𝐒𝐄𝐂𝐑𝐄𝐓 - 𝐂𝐋𝐔𝐁 znači da su svi primjeri koji su udaljeni koliko taj na indeksu i ili manje pozitivni, a ostali negativni
drugim riječima, prvo staviš da su svi pozitivni, pa da su svi osim najudaljenijeg pozitivni i tako dalje
ppooww
𝐓𝐇𝐄 𝐒𝐄𝐂𝐑𝐄𝐓 - 𝐂𝐋𝐔𝐁 Mene je to isto zbunjivalo, ali u biti, nakon što rangiraš primjere po udaljenosti (x5, x3, x4, x2). Ne sjećam se sad točno jel takav bio redoslijed. Ali onda prvo kažeš (postaviš prag) da su svi ti primjeri isti ko referentni primjer (x1). Znači gledaš kao da su svi označeni s (1, 1, 1, 1). Uspoređuješ te oznake s njihovim stvarnim oznaka i prebrojiš TP, FP, TN i sl. U sljedećem koraku, postavljaš oznake na (1, 1, 1, 0) i opet radiš istu usporedbu sa stvarnim oznakama. Onda ponoviš s (1, 1, 0, 0), i na kraju s (1, 0, 0, 0).
boogie_woogie
Zna netko ovaj?

BillIK
nika_1999 ako imaš max zauzeće 642, a jedan parametar zauzima 4 bajta, znači da imaš max 624/4 = 156 parametara.
Postaviš si jednadžbu za računanje broja parametara RNN-a kao inače i izjednačiš s 156 tj. h * h + h * x + h * 1 + y * h + y * 1 = 156
x i y znaš iz veličine vokabulara i samo, a biase su 0. uvrstiš to u jednadžbu i dobiješ traženi h
Dimenzija skrivenog sloja ti je onda h*h
boogie_woogie
BillIK A kako dobiti x i y iz velicine vokabulara?
faboche
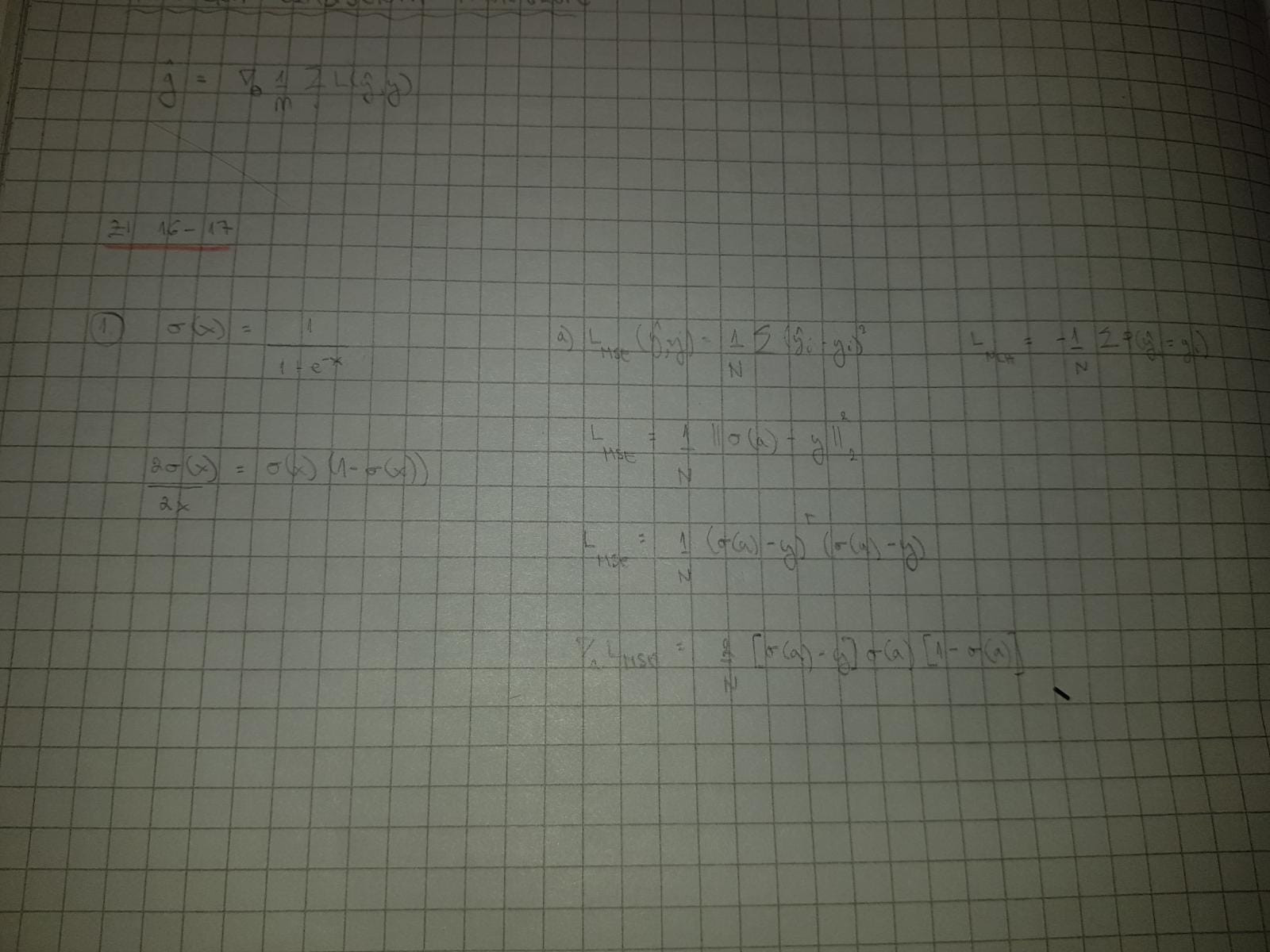
Zna li netko rijesiti ZI 16/17 1.zdk? Ovo je moja ideja, samo neznam dalje i nisam siguran je li ovo uopce dobro. (a je afina transformacija u zadnjem sloju)
Ryder


ima li netko postupak za ova dva?
branimir1999

Je li ovdje odgovor T * D ili T + D -1? Pitam jer ispod argumentira da mozes paralelno s obje strane krenuti, a u prezentacijama nema ni riječi o ovome
paradizot
branimir1999 ja mislim da je T+D-1 jer se u vremenu T prode kroz taj dvosmjerni sloj i onda imas jos D-1 slojeva duboke mreze
ErnestHemingway
debeli gmaz Ali svaki sloj moraš proć T puta
paradizot
Alfetta 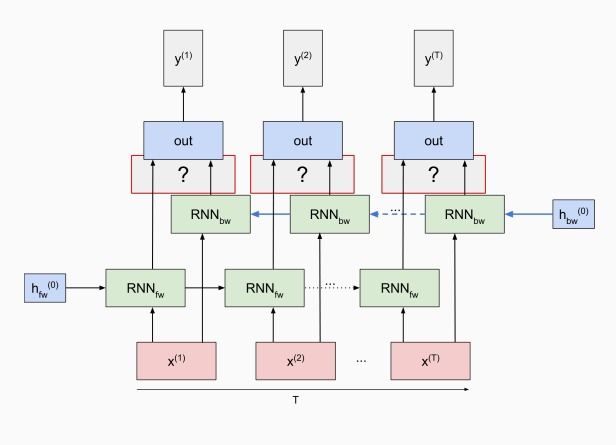
hmm, ja san to gleda ka da iman prvi dvosmjeni sloj i onda na mistu ovih upitnika ide normalna dubkoga mreza s nekin obicnin slojevima, ali evo nisan vise siguran jel idu stalno dvosmjeni slojevi ili ne
Daeyarn
debeli gmaz zar nije da je svaki sloj dvosmjeran kako bi mu receptivno polje bilo svi podaci iz prethodnog sloja? na eye of sauron slajdu su u svakom sloju dvosmjerni rnn

ErnestHemingway
debeli gmaz Piše da je višeslojni RNN
Tompa007

zna neko zasto se u c) podzadatku mnozi za 0.5 tezine ?
ppooww
𝐓𝐇𝐄 𝐒𝐄𝐂𝐑𝐄𝐓 - 𝐂𝐋𝐔𝐁 S obzirom na to da smo koristili dropout tijekom ucenja, trebamo to nekako uzet u obzir i prilikom testiranja tj. eksploatacije. Dropout u fazi testiranja se može aproksimirati skaliranjem tezina, u ovom slucaju sa 0.5 jer su s tom vjerojatnoscu dropoutani i podaci tijekom ucenja. Neka me netko ispravi ako sam u krivu.
Tompa007
pp A recimo da su razlicite vjerojatnosti po dimenzijama X kako bi onda rijesili to ?