[DUBUCE1] 4. laboratorijska vježba - 2021/2022
[obrisani korisnik]

Ovo mi izbacuje za conv2d unutar sekvencijalnog modela. Koliko znam, Parameter nasljeđuje Tensor, pa mi nema smisla + nisam sigurna kako bih popravila.
Ima netko sličan problem?
micho
[obrisani korisnik] Parameterje podklasa Tensora, pa svejedno to trebaš eksplicitno prebaciti u tensor jer ponašanje nije isto (niti ima garancije da će stvari imati istu semantiku).
Ono što bi se dogodilo je da ako ima ijedno mjesto gdje se taj tensor može dodati u parametre sloja, oni će biti automatski zapamćeni (jer to je razlika između Parameter i Tensor). Ovo u najboljem slučaju može redundantno optimizirati te inpute, u najgorem slučaju može mijenjati gradijent ili izazvati Null Reference (nakon što se sporni tenzor makne iz memorije nekim bugom). U principu za očekivati je memory leak.
tre_besty
Jel itko kuzi sto oni zele u 3. zadatku u implementaciji IdentityModel klase? Treba li get_features samo vracati samu sliku 28×28, ili trebamo tipa dodati jedan linearni sloj 28×28 pa da get_features vraca reprezentaciju slike 28×28. I trebamo li u toj funkciji implementirati opet i loss, jer mi nije bas jasno zele li oni da mi taj model treniramo il sto?
Ako je ovo prvo onda mi nije jasno kako bi trebali tu model uciti jer doslovno onda nema model.parameters() koji se pozivaju u optimizeru. Ako je ovo drugo s jednim linearnim slojem 28×28 onda mi ispadne precudno, jer kad tako implementiram svejedno dobijem dost dobar score na test podacima, oko 82%, a imam osjecaj kao je poanta tu da model ne bi trebao imati tako dobre performanse, nez.
Emma63194
luk Ja sam uzela doslovno sliku i prepisala sam loss funckiju iz prijašnjeg modela. Isto mi ispadne oko 82%, dok mi prvi model daje točnost oko 70%.
Ne znam je li to dobro. Ako je, možda je odgovor taj što su vizualno slike (iz istog razreda) jako jako slične (crna pozadina, bijele brojke - uglavnom na sredini) pa onda ispadne s L2 normom da su vektori dosta blizu.
Možda, ako bi se prvi model trenirao dulje od 3 epohe, možda bi onda davao bolje rezultate?
Rene
Može neko objasnit što bi get_features metoda trebala radit? Nije mi baš najjasnije
faboche
Rene Takoder, vezano uz to mi nije jasno kako bi trebalo povezati ove blokove za model metrickog ugradivanja
Emma63194
Rene Ako misliš na metodu get_features iz drugog zadatka, ja sam shvatila da je ona umjesto forward metode koju bi inače imao razred koji nasljeđuje nn.Module. Na kraju prilagodiš samo da metoda vrati Tensor koji je dimenzija BATCH_SIZE x EMB_SIZE.
Emma63194
Rene
Emma63194 da to sam na kraju i napravio i radi dobro, ali ne kontam čemu izmišljanje novih imena funkcija
btw. ako može neko podijeliti grafove iz zadnjeg zadatka bio bih zahvalan
micho
Rene Ima smisla jer Module.__call__ koristi i hookove koje potencijalno ne želiš koristiti u ovom slučaju. Ako implementiraš forward onda će automatski __call__ pozivati njega. Ovako praktički siliš korisnika da ili koristi get_features direktno i time izbjegne nuspojave, ili da shadowa defaultni __call__ ako baš želi pozivati objekt kao funkciju, pa opet izbjegne nuspojave.
Emma63194
Rene ako može neko podijeliti grafove iz zadnjeg zadatka bio bih zahvalan
Meni je ovako ispalo:

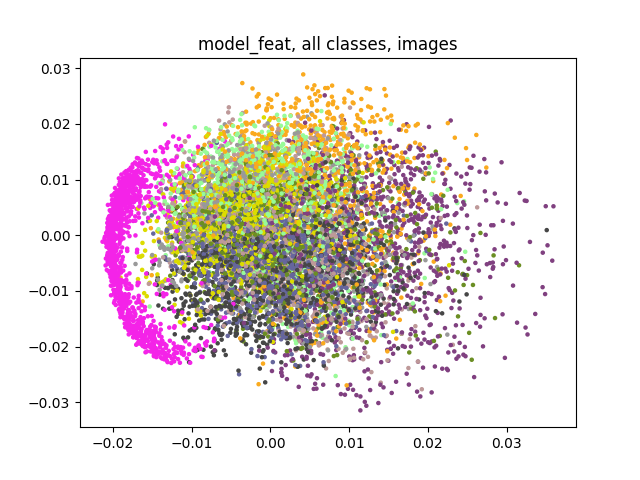

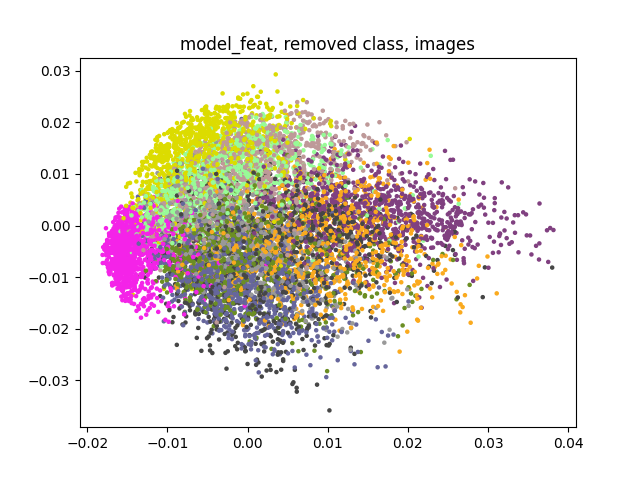




model_feat mi je model koji koristi vektore iz prostora značajki, dok model_id samo sliku uzima.
Jel nam išta slično izgledaju grafovi?
Rene
Emma63194 meni prvi model ima cca 97% tocnost, a drugi cca 82%. IdentityModel mi samo u get_features reshapea ulaz, ne učim ga uopće
Emma63194
Rene meni prvi model ima cca 97% tocnost
Unutar 3 epohe?
To je brutalno. Jesi nešto posebno radio da dobiješ takav rezultat ili je samo radilo tako iz prve?
ppooww
Rene Kak ga reshapeas? torch.reshape(img, (img.shape[0], 1))? Nije mi bas najjasniji taj zadatak pa je bilo kakva pomoc dobrodosla
Rene
Emma63194 nista posebno, samo implementirao po uputama
Mislim da je to ocekivano jer je MNIST dosta lagan dataset, al mozda san i ja nesto gadno zajeba
Ducky
Emma63194 pfff, meni je 3136.00% nakon 0. epohe
Tompa007
Ovaj lab nema na gitu? Mico ga nije rjesavo ? E moj mico pa nista neznas
BillIK
što bi bili parametri num_maps_in, num_maps_out u BNReluConv klasi?
[obrisani korisnik]
Ima nekoga da ne planira doći na svoj termin u srijedu/četvrtak da se zamijeni za moj u utorak?
indythedog
[obrisani korisnik] Ja ti imam termin u srijedu u 9 ujutro, ako ti paše javi se u box
Tompa007
Ducky I meni je tako, si rijesio to ?
Tompa007
Ducky Provjeri si output shape iz forwards treba ti biti , BATCH * EMB , a ne BATCH * EMB * 1 * 1
steker
Jel moze neko napisat arhitekturu simplemetricembeddinga koja bi trebala bit
Emma63194
- BNReluConv
- max pool
- BNReluConv
- max pool
- BNReluConv
- global average pool
steker
Emma63194 mislim koliko treba bit ulaz i izlaz za svaki layer