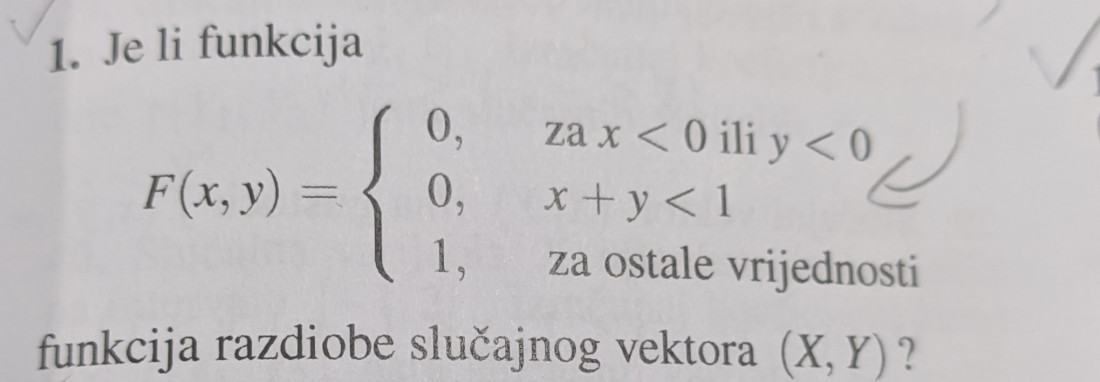dinoo ono sto mi pada na pamet je da kad gledas po definiciji F(x,y) = P(X < x, Y < y), u svim tockama je ili 0 ili 1, ove tocke za koje je P(X < x, Y < y) = 1 znaci da je vjerojatnost 1 da je slucajna varijabla poprimila vrijednosti strogo manje od tih zadanih u (x,y), tako za svaku tocku (x,y) za koju je P=1 se spustas jer je poprimljena vrijednost strogo manja, sve dok odjednom naglo ne dode do tocke za koju je P=0, dakle nju ne moze isto poprimit a ne moze ni jednu manju od nje, po definiciji
drugim rijecima, u funkciji razdiobe, izmedu poprimanja vrijednosti 0 i 1 uvijek mora postojat jos neka vrijednost koju vjerojatnost poprima, to jer je F(x) = P(X < x) a ne = P(X <= x)
(ako se ne varam)