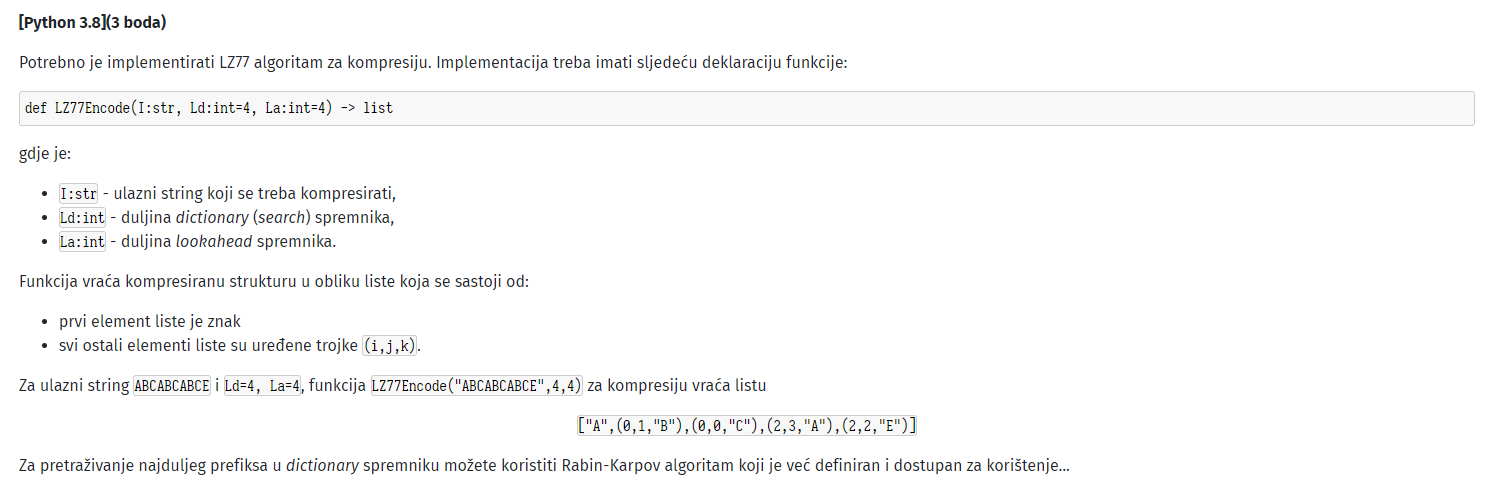
Zadatak Vam je implementirati Huffmanov enkoder koristeći prioritetni red. Numerička tolerancija je . U postupku izgradnje stabla, lijevo dijete uvijek neka bude ono manje, a desno neka bude veće (pogledajte napomenu 1). Ovo će osigurati jednoznačnost koda. Testiranje se provodi nad odabranim i slučajno generiranim primjerima. Svi testovi se provode nad kodnom tablicom.
Već Vam je složena većina koda, ali morate ispravno dovršiti slijedeće:
metodu lt unutar klase Node na način da ispravno uspoređuje čvorove stabla. U usporedbama brojeva sa pomičnim zarezom, pazite na numeričku preciznost! Ovu metodu koristi prioritetni red za određivanje redoslijeda čvorova.
metodu Huffman_tree na način da izgradi valjano Huffmanovo stablo
Mjesta gdje trebate unijeti kod su označena sa TODO. Za prioritetni red se preporuča korištenje heapq iz pythonove standardne programske knjižnice koja koristi min-heap za održavanje reda.
Ostatak koda riješava probleme izgradnje kodne tablice i enkodiranja.
Kod
U prostor za odgovore zalijepite CIJELI kod (popunjen, naravno).
import heapq
TOL_DEC = 3
TOLERANCE = 10**-TOL_DEC
class Node:
"""Node in a Huffman tree
"""
def __init__(self, prob, symbol, left=None, right=None):
self.prob = prob # probability of symbol
self.symbol = symbol
self.left = left
self.right = right
# incoming tree direction to node (0/1) - root has ''
self.code = ''
def __lt__(self, other: 'Node') -> bool:
"""enables comparisons between objects
Args:
other (Node): other object in comparison
Returns:
bool: True if self is LESS THAN other,
False otherwise
"""
# TODO: ovdje dodajte svoj kod za usporedbu. Pazite na numeričku toleranciju!
pass
def Huffman_tree(symbol_with_probs: dict) -> Node:
"""Builds Huffman tree
Args:
symbol_with_probs (dict): dictionary symbol-probability that describes the problem
Returns:
Node: root of the built Huffman tree
"""
symbols = symbol_with_probs.keys()
nodes_queue = []
# TODO: ovdje dovršite izgradnju stabla
# HINT: spajanje dva stringa s1 i s2 u sortirani se moze postici sa: ''.join(sorted(s1+s2))
# HINT: za rad sa prioritetnim redom vam mogu zatrebati metode heapq.heappop i heapq.heappush
return nodes_queue[0]
####################### IT'S BETTER NOT TO MODIFY THE CODE BELOW ##############
def calculate_codes(node: Node, val: str = '', codes=dict()) -> dict:
# calculates codewords for Huffman subtree starting from node
newVal = val + str(node.code)
if(node.left):
calculate_codes(node.left, newVal, codes)
if(node.right):
calculate_codes(node.right, newVal, codes)
if(not node.left and not node.right):
codes[node.symbol] = newVal
return codes
def Huffman_encode(data: str, coding: dict) -> str:
# encodes
encoding_output = []
for c in data:
encoding_output.append(coding[c])
string = ''.join([str(item) for item in encoding_output])
return string
def Huffman_decode(encoded_data: str, huffman_tree: Node) -> str:
tree_head = huffman_tree
decoded_output = []
for x in encoded_data:
if x == '1':
huffman_tree = huffman_tree.right
elif x == '0':
huffman_tree = huffman_tree.left
# check if leaf
if huffman_tree.left is None and huffman_tree.right is None:
decoded_output.append(huffman_tree.symbol)
huffman_tree = tree_head
string = ''.join([str(item) for item in decoded_output])
return string
def roundToDecimals(num: float, decimals: int) -> float:
"""Rounds number to significant decimals
Args:
num (float): number to round
decimals (int): number of significant decimals
Returns:
float: rounded number
"""
return round(num*10**decimals)/10**decimals
Ovdje Vam je kod koji možete koristiti za testiranje
Kod za isprobavanje i testiranje
Ovaj kod nemojte kopirati u prostor za rješenje, već ga koristite lokalno u svojoj razvojnoj okolini.
symbols_with_probs={'A':0.13,'B':0.21,'C':0.39,'D':0.19,'E':0.08}
print('problem: ', symbols_with_probs)
tree=Huffman_tree(symbols_with_probs)
huffman_code = calculate_codes(tree)
print('encoding:',huffman_code)
data = 'DEBADE'
print('original text: ',data)
print('-------ENCODE--------')
enc=Huffman_encode(data,huffman_code)
print('data encoded: ',enc)
print('-------DECODE--------')
print('data decoded back: ',Huffman_decode(enc,tree))
""" # ispravan izlaz
problem: {'A': 0.13, 'B': 0.21, 'C': 0.39, 'D': 0.19, 'E': 0.08}
encoding: {'D': '00', 'E': '010', 'A': '011', 'B': '10', 'C': '11'}
original text: DEBADE
-------ENCODE--------
data encoded: 000101001100010
-------DECODE--------
data decoded back: DEBADE
"""
Napomena 1
U postupku izgradnje kodne tablice, koristite sljedeći tie-breaker (razrješavanje situacija kada imate izjednačene usporedbe vjerojatnosti)…
Uvedimo imenovanje čvora u Huffmanovom stablu na sljedeći način:
ako je list, tada mu je ime njegov pripadni simbol
ako je unutarnji čvor, neka mu je ime uzlazno sortirana konkatenacija simbola njegovih listova. Npr. ako su u podstablu tog čvora listovi simbola ‘C’, ‘A’, ‘E’ onda će ime tog unutarnjeg čvora biti ‘ACE’.
Ako dva čvora imaju jednake vjerojatnosti, tada se manjim čvorom smatra onaj koji ima leksikografski manje ime. Primjer istinitih usporedbi su: ‘AB’ < ‘AC’ < ‘ACE’ te dodatno ‘BC’<‘E’.
NAPOMENA 2
Pazite na uvlačenja (indentacije) - koristite samo SPACE ili samo TAB
Možete koristiti print funkciju za ispis međurezultata
Edgar koristi Python verziju 3.8, tako da vam možda neke funkcionalnosti iz novijih (3.9+) ili starijih (2.x) verzija neće podržavati
Molimo da pišete svoj vlastiti kod. Kodove u skripti možete koristiti za orijentaciju. Edgar ima mogućnost otkrivanja plagijata i ta će mogućnost biti korištena na ovom zadatku.