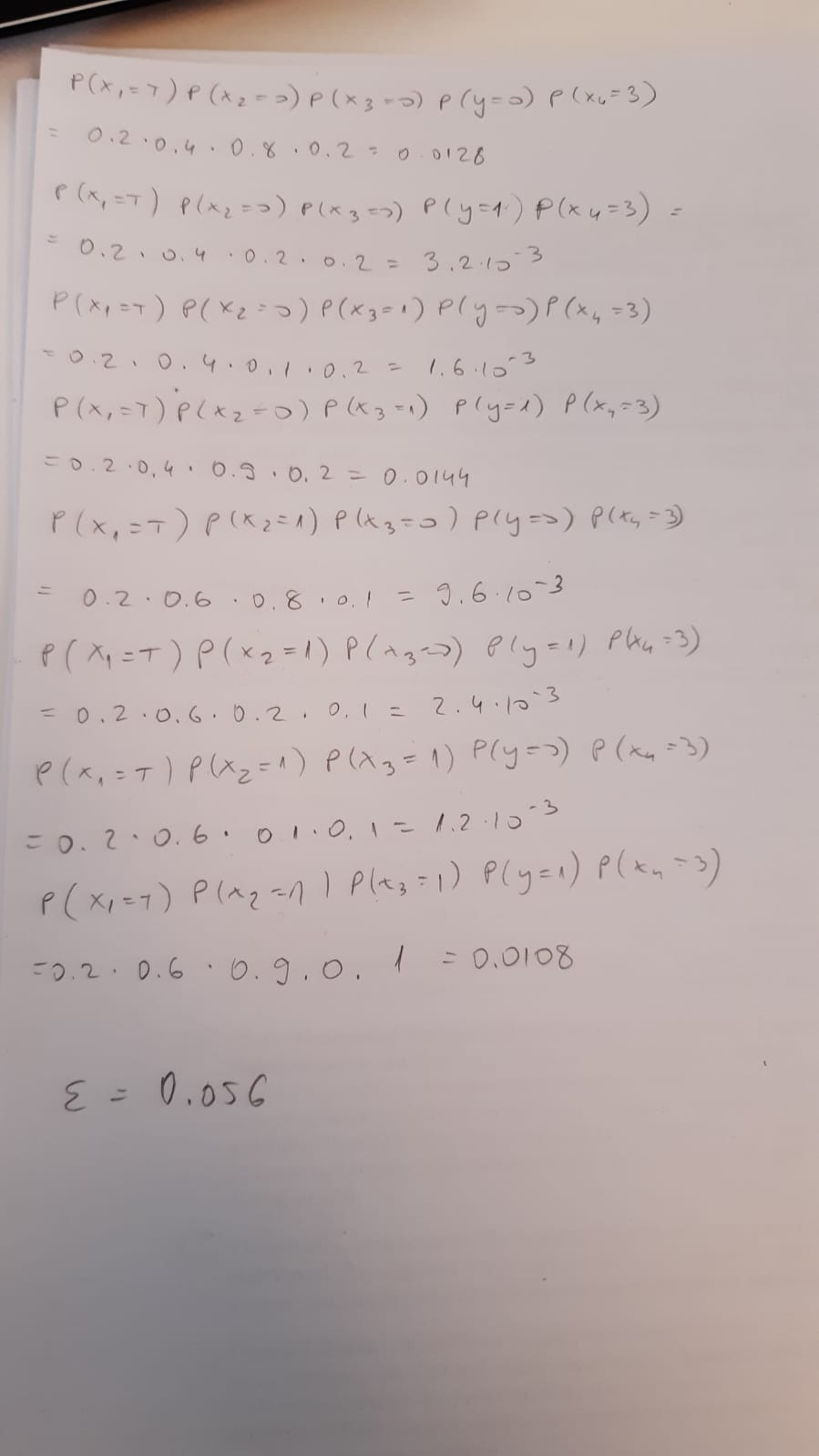Jel itko moze objasniti 10., 17. i 24. iz ovogodišnjeg MI-a kako se rade.
10.

Tocno je 50/32 i 25/16. Ja stalno dobivam 50/21. Za OVR uzmem N klasifikatora (4) i svaki se trenira sa 1000 primjera, sto daje za svaki Grammovu matricu od 1 000 000 elemenata, i tako puta 4 puta (4 000 000). Za OVR imam K povrh 2 (6) klasifikatora, i imaju razlicito elemenata, ovisno o broju primjera(400+400, 400+100 * 4, i 100+100). U sumi dobijem 1 680 000 elemenata u Grammovoj matrici i iz toga omjer 50:21
17.

Točan je A. Ovdje sam izračunao h(x) za svaki x, po tome odredio koji je y, i onda to ubacio u formulu za ovisnost w i alpha 5. stranica ovdje. Time sam dobio sistem od 4 jednadžbe sa 4 nepoznanice (alphe) i od toga uvijek dobio da nema rješenja. Jel to točan način za radit pa ja krivo rješavam sistem jednadžbi ili ima neki drugi način?
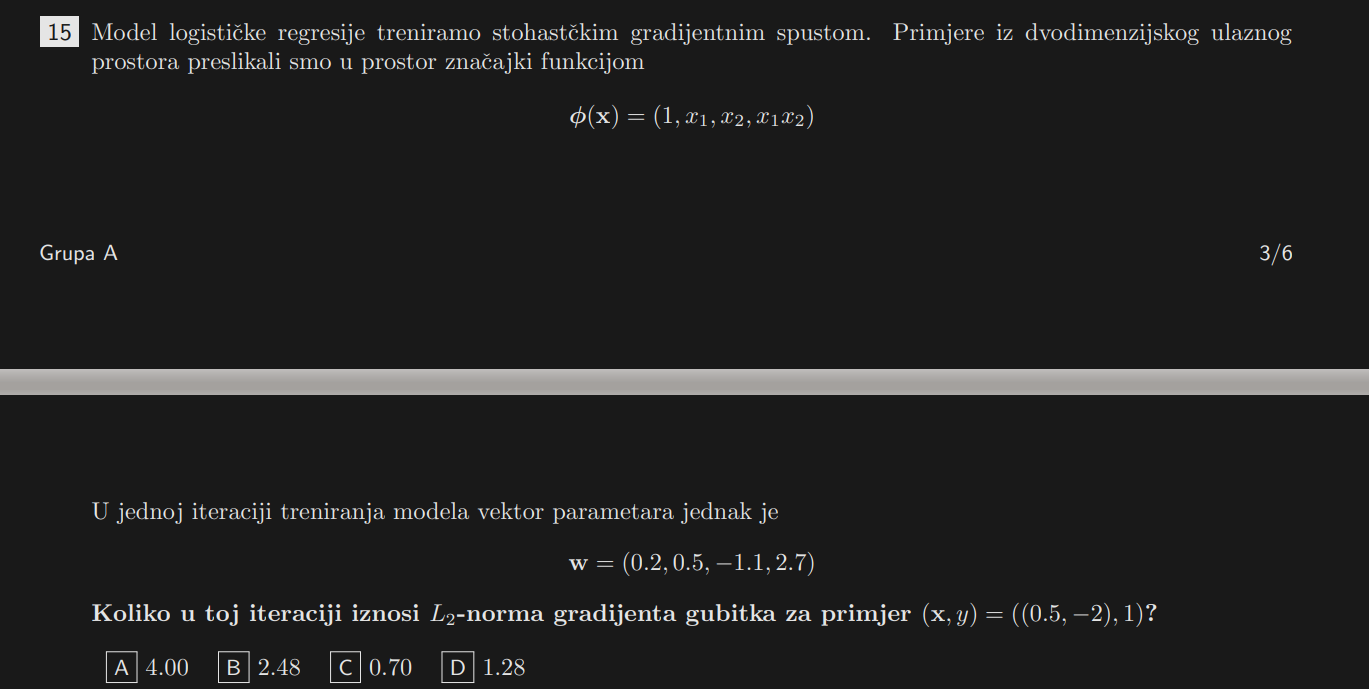
24.

Ovdje je točno pod D. Mogu navuć brojke al mi nije baš 100% jasno. 501 parametar optimazacije mi je jasno jer imamo 500 jezgrenih funkcija (za svaki primjer jednu) u jezgrenom stroju, plus φ1=1. Al kako su došli do 3079 parametara? Sta ne bi bilo da za svaki od 38 prototipa imamo samo po jedan skalar w?